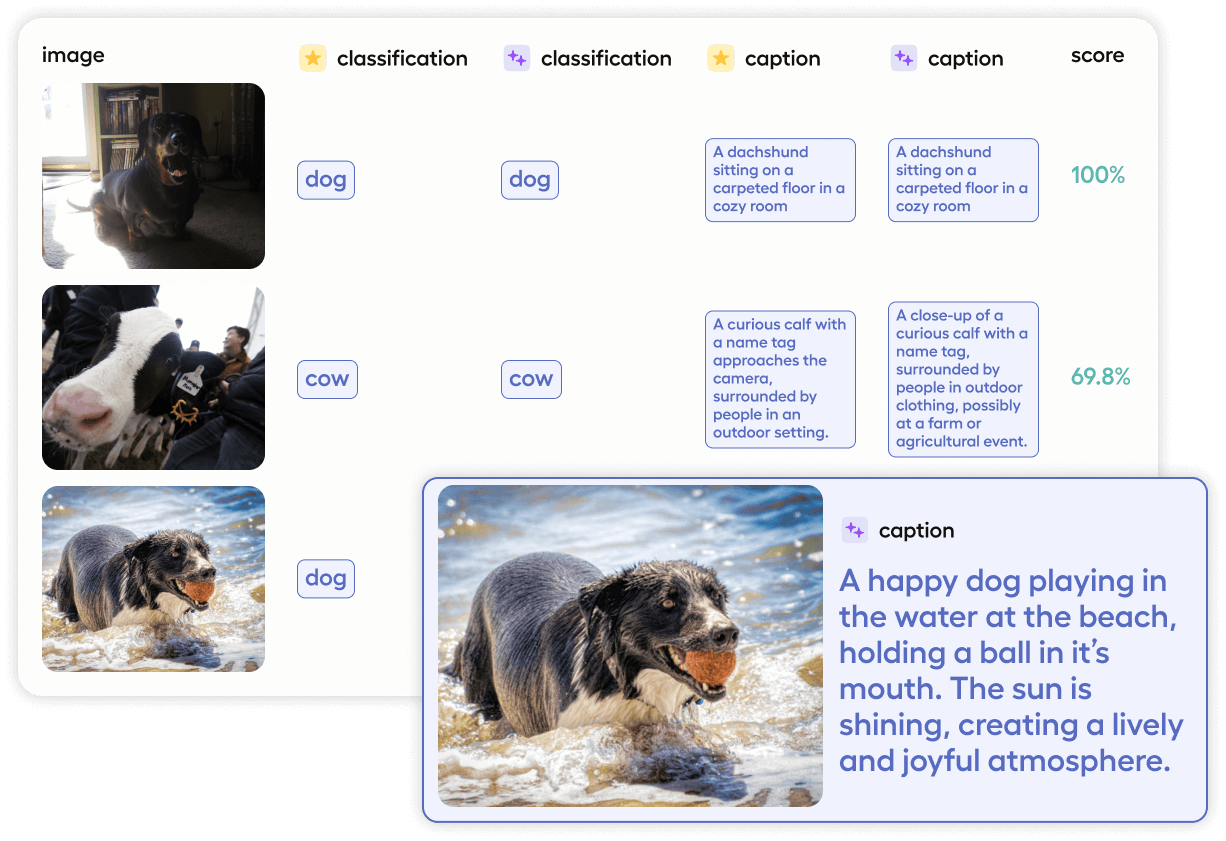
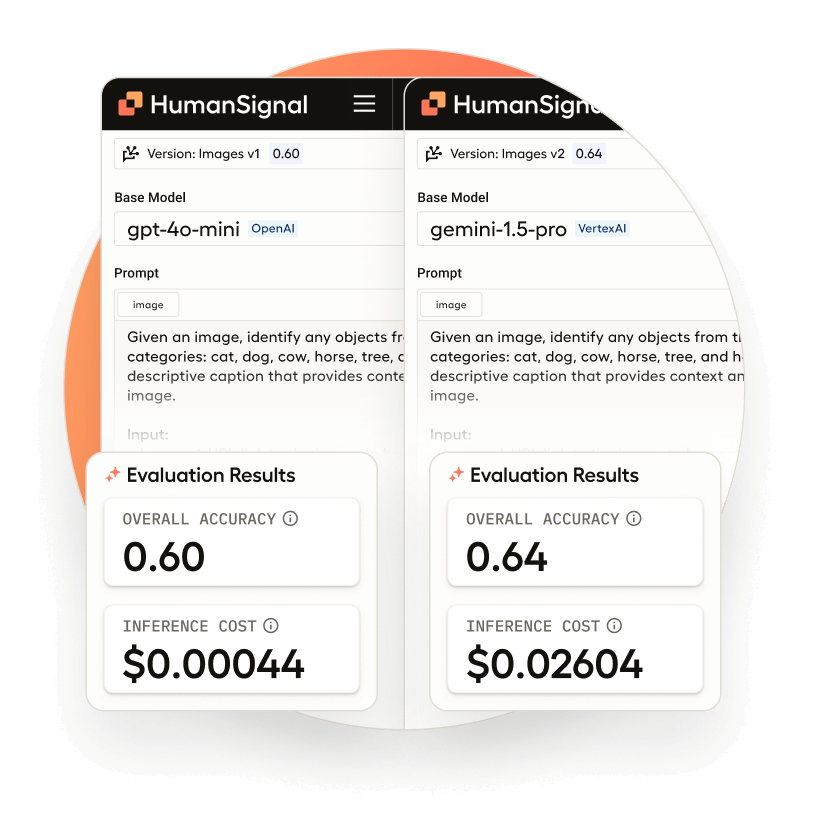
Scalable model evaluation and turnkey pre-labeling
Automatically generate annotations, compare models, and evaluate outputs with LLM-as-a-judge workflows that support benchmark-grade testing and quality scoring.
Works with popular LLMs and custom endpoints